Triton in Towhee
Triton is an inference serving software that streamlines AI inferencing, and Towhee uses Triton to provide model inference and acceleration.
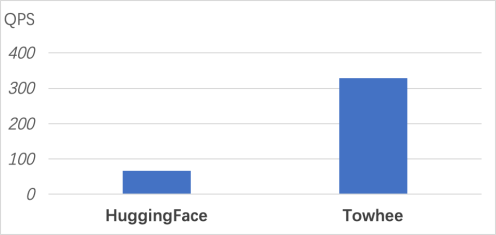
For example, we tested the performance of two CLIP pipelines on the same machine (64 cores, GeForce RTX 3080), one based on HuggingFace and the other using Towhee&Triton, Towhee is 5x faster than Huggingface.
Prerequisites
Example
There is an example of using towhee to start a triton server with a text image search pipeline, you can also refer to this to start your own pipeline.
Create Pipeline
When creating a pipeline, we can specify config with AutoConfig to set the configuration. It will work when starting the Triton Model, and the following example shows how to create a pipeline in Triton with config = AutoConfig.TritonGPUConfig().
from towhee import pipe, ops, AutoConfig
p = (
pipe.input('url')
.map('url', 'image', ops.image_decode.cv2_rgb())
.map('image', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image'), config=AutoConfig.TritonGPUConfig())
.output('vec')
)
Build Image
import towhee
towhee.build_docker_image(
dc_pipeline=p,
image_name='clip:v1',
cuda_version='11.7', # '117dev' for developer
format_priority=['onnx'],
parallelism=4,
inference_server='triton'
)
Then we can run docker images command and will list the built clip:v1 image.
Start Triton Server
Run docker image with tritonserver command to start triton server.
$ docker run -td --gpus=all --shm-size=1g \
-p 8000:8000 -p 8001:8001 -p 8002:8002 \
clip:v1 \
tritonserver --model-repository=/workspace/models
After starting the server, we can run docker logs <container id> to view the logs. When you see the following logs, it means that the server started successfully:
Started GRPCInferenceService at 0.0.0.0:8001
Started HTTPService at 0.0.0.0:8000
Started Metrics Service at 0.0.0.0:8002
Create model in your own server
In addition, we can create models from a pipeline. This is a step in the building docker image, but we can also do independently to get the models in our own server. We take a triton’s official inference server as an example:
Start the Triton Inference Server container, here we take tritonsever
22.07as an example, replace it with proper version according to your cuda version.docker run --shm-size=1g --ulimit memlock=-1 -p 8000:8000 -p 8001:8001 -p 8002:8002 --ulimit stack=67108864 -ti nvcr.io/nvidia/tritonserver:22.07-py3
Replace
22.07with proper version according to your cuda version, refer to NvidiaInside the container, install twohee
pip install towhee
Create models
import towhee from towhee import pipe, ops, AutoConfig p = ( pipe.input('url') .map('url', 'image', ops.image_decode.cv2_rgb()) .map('image', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image'), config=AutoConfig.TritonGPUConfig()) .output('vec') ) towhee.build_pipeline_model( dc_pipeline=p, model_root='models', format_priority=['onnx'], parallelism=4, server='triton' )
We can find
modelsfolder in CWD with following structure:models ├── image-text-embedding.clip-1 │ ├── 1 │ │ └── model.onnx │ └── config.pbtxt └── pipeline ├── 1 │ ├── model.py │ └── pipe.pickle └── config.pbtxt
Start the Triton server
tritonserver --model-repository `pwd`/models
Then we should see the same info as in the previous step.
Started GRPCInferenceService at 0.0.0.0:8001
Started HTTPService at 0.0.0.0:8000
Started Metrics Service at 0.0.0.0:8002
Remote Serving
Then we can use triton_client to request the result with the url.
The url format is your-ip-address:your-grpc-port, you need modify the ip according you env.
from towhee import triton_client
# run with triton client
client = triton_client.Client(url='localhost:8000')
# run data
data = 'https://github.com/towhee-io/towhee/raw/main/towhee_logo.png'
res = client(data)
# run batch data
data = ['https://github.com/towhee-io/towhee/raw/main/towhee_logo.png'] * 3
res = client.batch(data)
Advanced
Pipeline Configuration
When building the image, we need to specify the following parameters:
dc_pipeline: towhee pipelineimage_name: the name of the imagecuda_verion: the version of CUDAformat_priority: the priority list of the model, defaults to [‘onnx’]inference_server: the inference server, defaults to ‘triton’
Docker Configuration
You can set the Docker Command Options when start triton server, such as set gpus and she-size.
Q&A
Why the docker image is very large?
The base image (nvidia/tritonserver) itself is large, and there are many packages related to the package model (PyTorch, Onnxruntime, etc.) that need to be installed.
How to debug my pipeline in triton?
Once you have started triton server, you can run into the container to modify the code with
docker exec -ti <container_id> bashcommand, and then manually start the triton service in container withtritonserver --model-repository=/workspace/models --grpc-port=<your-port>.
